Odrobina kontekstu
Czasy dostaw to trudny temat.
W Lisku klient w swojej aplikacji widzi jeden licznik po złożeniu zamówienia. Licznik, który mówi mu, kiedy w progu drzwi jego domu bądź biura pojawi się kurier z wyczekiwanym zamówieniem. Po naszej stronie jednak w czasie, który prezentuje licznik musi wydarzyć się mnóstwo procesów, zarówno technicznych jak i operacyjnych. Osoby na magazynie muszą potwierdzić przyjęcie zamówienia oraz skompletować je odhaczając każdy produkt w dedykowanej aplikacji kurierskiej. Potem, po krótkim czasie oczekiwania zamówienie zostaje odebrane przez kuriera, który transportuje je pod adres klienta, często dostarczając po drodze zamówienia innych klientów.
Przewidzenie w jakim czasie uda się zrealizować wszystkie te procesy jest doprawdy karkołomnym zadaniem. Tym bardziej, że wpływa na nie wiele czynników poza naszą kontrolą, takich jak pogoda czy ruch drogowy.
Jako inżynier, z technicznego punktu widzenia chciałbym przewidywać czas dostawy w możliwie najwierniejszy sposób. Biorąc pod uwagę aktualne warunki drogowe, odległość do celu, pogodę, dostępną ilość kurierów czy chociażby aktualne obciążenie magazynu. Chciałbym wyśrubować wszystkie statystyczne metryki do granic tego, co jest technicznie możliwe.
Istnieje jednak też biznesowy punkt widzenia. Z jego perspektywy powinniśmy zwracać czas możliwie wiernie, ale także z odpowiednim zapasem, by klient czuł się pozytywnie zaskoczony, gdy kurier zawita do jego drzwi zbyt wcześnie, a nie negatywnie, gdy zamówienie dotrze zbyt późno. Czas dostawy wyświetlony użytkownikowi nie powinien się także zmieniać zbyt często, by nie powodować dodatkowej frustracji. Do tego dochodzi koszt wdrożenia rozwiązania i jego późniejszego utrzymania.
Stan zastany: Algorytm symulujący dostawę
Gdy przyszedłem do Liska czas dostawy przewidywał algorytm starający się zasymulować cały proces dostawy, który opisywałem wyżej. Odpowiedzialna za to była jedna klasa mająca aż 1562 linie kodu!
Algorytm na początku pobierał aktualny stan operacyjny z bazy danych (liczba aktywnych zamówień, ilość dostępnych kurierów itp.) oraz ustawiał licznik czasu na aktualną godzinę rzeczywistą. Później, w pętli dodawał do tego licznika stałą wartość 30 sekund oraz, zakładając że pewne operacje zajmują pracownikom stałą ilość czasu, sprawdzał w jakim stanie powinni znaleźć się kurierzy i zamówienia przy aktualnej wartości licznika. Pętla przerywała się, gdy w symulacji kurier został przypisany do szukanego zamówienia, a aktualna wartość licznika zwracana była jako przewidywany czas wyjazdu kuriera. Do tej wartości dodawany był czas przejazdu, który liczony był na podstawie odległości do klienta oraz średniej prędkości kurierów.
Rozwiązanie to nie zdało rezultatu dając w praktyce losowe rezultaty. Dodatkowo kod algorytmu nie był najwyższej jakości, przez co jego utrzymanie stanowiło koszmar. Musieliśmy więc coś z tym zrobić :)
Poniżej przykładowy wycinek kodu, byśmy wiedzieli o czym mowa:
case CourierStatus.AtLocation:
if (order.OrderStackId == null)
{
deliveryTime = await deliverySpeedService.GetDeliveryTimeInS(order);
totalTimeInS = runtimeSettingsService.AvgAtLocationTimeInSeconds
+ deliveryTime;
}
else
{
var stackInfo = await ordersStackService.GetEstimationStackInfo(order.OrderStackId.Value);
var orderInfo = stackInfo.Orders.FirstOrDefault(e => e.Id == order.Id);
if (orderInfo == null)
{
var msg = $"[Estimation][{courierStatus}] Could not find order {order.Id} in {GetStackInfoLog(stackInfo, false)}";
logger.LogInformation(msg);
deliveryTime = await deliverySpeedService.GetDeliveryTimeInS(order);
totalTimeInS = runtimeSettingsService.AvgAtLocationTimeInSeconds
+ deliveryTime;
}
else if (orderInfo.IsLastOrderInStack)
{
totalTimeInS = runtimeSettingsService.AvgAtLocationTimeInSeconds
+ stackInfo.ReturnToDsTimeInS;
}
else
{
totalTimeInS = runtimeSettingsService.AvgAtLocationTimeInSeconds;
}
}
break;
case CourierStatus.Returning:
deliveryTime = await deliverySpeedService.GetDeliveryTimeInS(order);
totalTimeInS = deliveryTime;
break;
default:
throw new ArgumentOutOfRangeException(nameof(courierStatus), $"Invalid status: {courierStatus}");
Iteracja I: Tabelka ze stałymi
W pierwszej iteracji chcieliśmy zastosować możliwie proste rozwiązanie, które nie będzie denerwować użytkowników i zapewni zgodność przewidywanego czasu z rzeczywistością. Postanowiliśmy więc utworzyć prostą tabelkę, która zawierałaby dwie wartości: liczbę aktualnie realizowanych zamówień oraz przewidywany czas dostawy. Nasza logika była prosta - największy wpływ na czas dostawy ma to, ile aktualnie mamy zamówień w realizacji, dlatego spróbujmy się na tym oprzeć i zobaczymy, jakie będą rezultaty.
Zaimplementowaliśmy więc rozwiązanie w którym zwracaliśmy userowi sztywną wartość z w/w tabeli, którą ręcznie tunowaliśmy na podstawie historii dostaw.
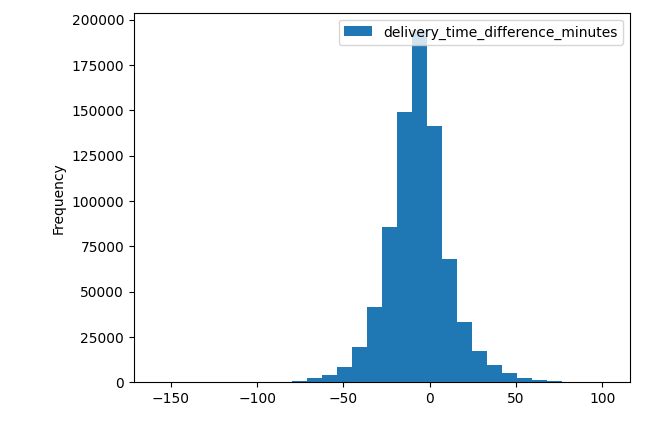
Algorytm nie zachwycał dokładnością, co obrazuje rozkład różnicy pomiędzy estymatą a rzeczywistym czasem dostawy podzielone na kwartyle zamówień:
- Q1: 304s
- Q2: 677s
- Q3: 1200s
Rozkład błędu rozwiązania z tabelką stałych. W osi X błąd w minutach. W osi Y ilość zamówień:
Dla nerdów podrzucam też metryki MAE, MSE i RMSE :)
- MAE: 869.055575803318
- MSE: 1333175.3878827186
- RMSE: 1154.6321439673843
Iteracja II: Prosta regresja liniowa
Model v1
Po pewnym czasie doszliśmy do wniosku, że warto spróbować wykorzystać w mądrzejszy sposób zbierane przez nas dane o dostawach. Postanowiliśmy więc wykorzystać regresję liniową, by wyszkolić prosty model, który zwróci nam czas dostawy.
Był to eksperyment, w związku z tym chcieliśmy maksymalnie skrócić czas poświęcany na cały proces, co wymusiło na nas kompromisy w kontekście ilości użytych przy uczeniu parametrów, jakości danych oraz narzędzi.
Postawiliśmy repozytorium z Jupyter Notebook, gdzie umieściliśmy cały proces, począwszy od zastosowanych zapytań do wyciągnięcia danych z bazy, przez ich przetwarzanie i ocenę, po sam nadzorowany proces szkolenia modelu. Samo szkolenie odbyło się przy pomocy biblioteki Scikit-Learn.
Użyliśmy następujących parametrów:
- Odległość od magazynu do mieszkania klienta
- Ilość produktów w zamówieniu
- Ilość fizycznych opakowań w zamówieniu
- Ilość zamówień będących w realizacji
- Ilość aktualnie pracujących osób
Były to czynniki, które było w miarę łatwo wyciągnąć z dostępnych nam danych (choć nie ukrywam, że wyliczenie ilości aktualnie pracujących osób z danych historycznych było wyzwaniem - ponieważ nigdzie nie trzymaliśmy takiej informacji). Oraz wydawały się one najbardziej istotne wg. posiadanej przez nas wiedzy operacyjnej oraz wg. matrycy korelacji.
Model ten osiągnął nieco lepsze rezultaty niż nasze rozwiązanie oparte o stałe w tabelkach osiągając RMSE równy 926 w porównaniu do 1154 w przypadku tabeli.
Postanowiliśmy wdrożyć to rozwiązanie, równocześnie opracowując jego ulepszoną wersję.
Model v2
W drugiej wersji modelu regresji liniowej dodaliśmy kolejne parametry, wkładając jednocześnie więcej pracy w analizę oraz przetwarzanie danych.
Dodaliśmy następujące parametry:
- Pochodne parametru odległości od magazynu do mieszkania klienta - dzięki temu mogliśmy modelem objąć nieliniową zależność odległości i czasu dostawy
- Współczynnik ilości kurierów / ilość zamówień - pozwala on na lepsze odzwierciedlenie w modelu jak obłożenie magazynu wpływa na czas dostawy
- Pora dnia - godziny szczytu mają wpływ na czas dostawy
- Dzień tygodnia - w weekendy mamy zdecydowanie większe obłożenie
- Dane pogodowe
- Temperatura
- Opady
- Zaśnieżenie
Model wykazał się znacznie wyższą skutecznością od swojego poprzednika oraz od tabelki ze stałymi. Poniżej różnica pomiędzy przewidywanym czasem dostawy a rzeczywistym podzielona na kwartyle zamówień:
- Q1: 217s
- Q2: 452s
- Q3: 780s
Rozkład błędu modelu v2. W osi X błąd w minutach. W osi Y ilość zamówień:
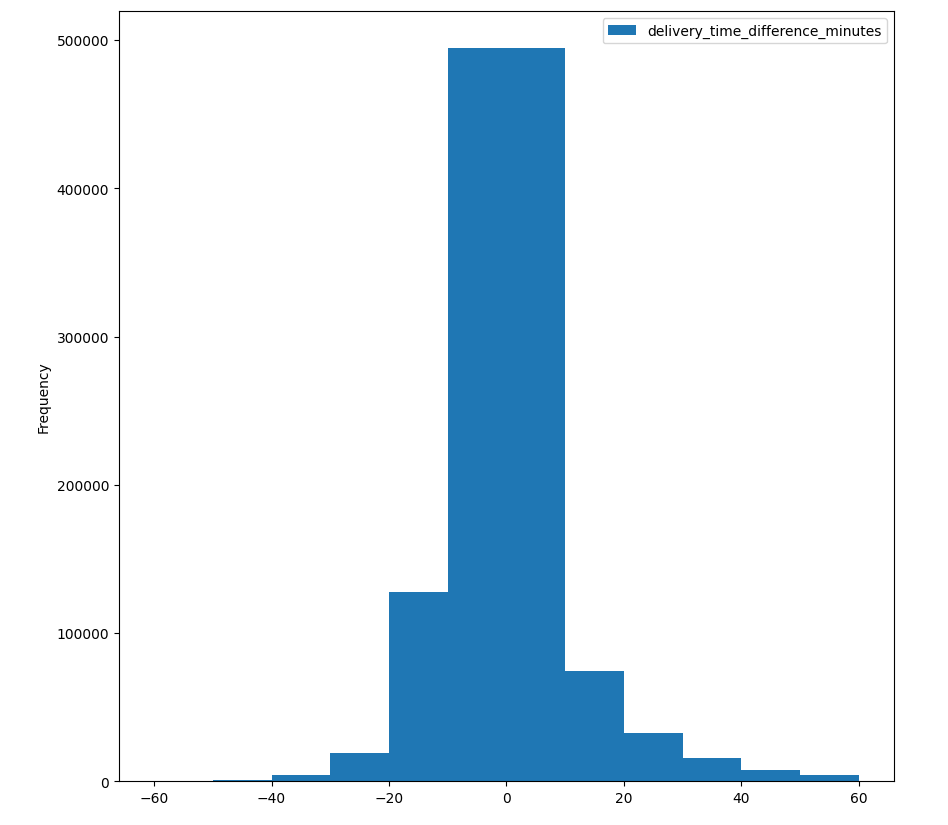
Widać jest znaczącą poprawę względem rozwiązania opartego o tabelkę ze stałymi. Udowodniło nam to, że uczenie maszynowe jest dobrym kierunkiem, w stronę którego warto podążać. Druga wersja modelu trafiła na produkcję niedługo po pierwszej.
Przez pewien okres staraliśmy się jeszcze poprawić wynik, dodając kolejne parametry czy dokonując tuningu danych. Nie powodowało to jednak wartościowej z biznesowego punktu widzenia poprawy wyników. Uznaliśmy więc, że dotarliśmy do kresu możliwości regresji liniowej, która bądź co bądź jest bardzo prostym rozwiązaniem, bardzo szybkim w implementacji przy skalarnych problemach jak czas dostawy, ale będącej jednocześnie mocno ograniczoną w kontekście modelowania nieliniowych zależności.
Tu także wrzucam metryki dla nerdów :)
- MAE: 605.560420453004
- MSE: 717012.7112698294
- RMSE: 846.7660310084655
Iteracja III: Sieć neuronowa
Postanowiliśmy więc spróbować wyszkolić na naszych danych sieć neuronową. Nie było to szczególnie trudne, ponieważ większość pracy z danymi wykonaliśmy podczas prac nad modelami regresji liniowej. Wystarczyło wykorzystać inny komponent biblioteki Scikit-Learn.
To rozwiązanie pozwoliło nam na skrócenie ogona w rozkładzie różnicy pomiędzy rzeczywistym czasem dostawy a przewidzianym, zwiększając udział zamówień w docelowym przedziale pomyłki +/- 10 min. Tak jak wcześniej w osi X mamy różnicę, a w osi Y ilość zamówień:
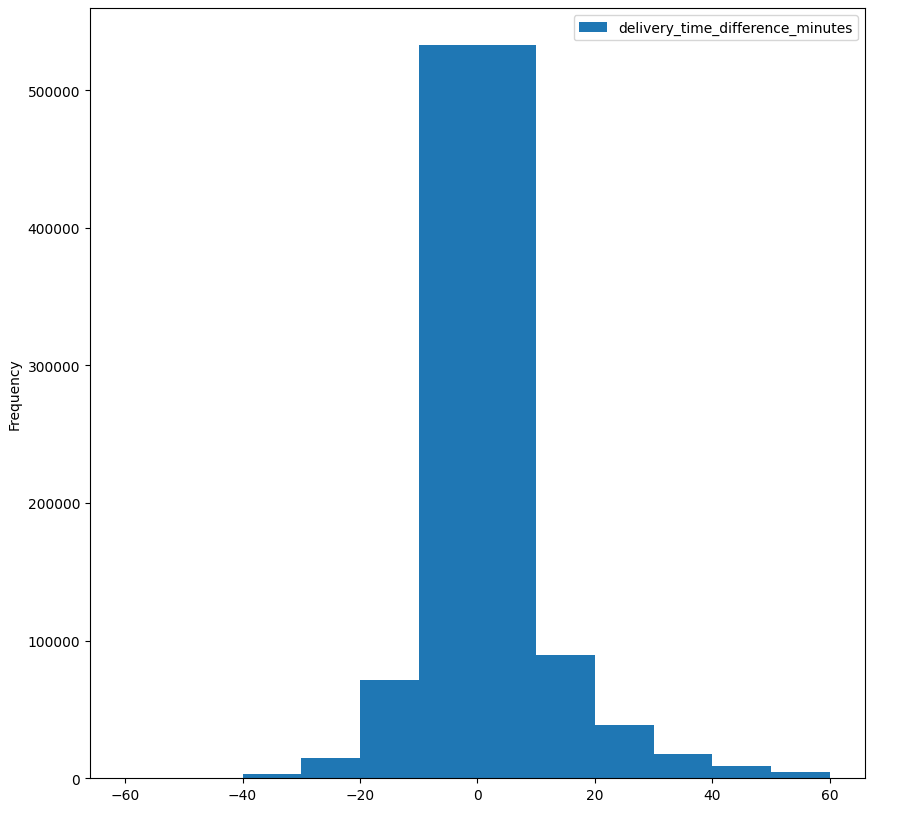
I także metryki dla nerdów :)
- MAE: 561.1074756562314
- MSE: 684910.2344233053
- RMSE: 827.5930367175072
Problem z siecią neuronową jest taki, że jej wdrożenie produkcyjne jest znacząco bardziej skomplikowane. W przypadku regresji liniowej wystarczy zaimplementować klasę, w której dodajemy do siebie parametry mnożąc je uprzednio przez stałe z wytrenowanego modelu:
public static class V2
{
public static double PredictDeliveryTime(
int distanceMeters,
double distanceMetersSqrt,
double distanceMetersPow2,
int orderItemsCount,
int physicalItemsCount,
int ordersInRealisationCount,
int workingCouriersCount,
double ordersCountCourierRatio,
int timeOfDay,
int dayOfWeek,
double temperature,
double precipitation,
double snowfraction,
double snowPrecipitation)
{
return
GetWeightedValue(distanceMeters, MagicHat.V2.DistanceMeters) +
GetWeightedValue(distanceMetersSqrt, MagicHat.V2.DistanceMetersSqrt) +
GetWeightedValue(distanceMetersPow2, MagicHat.V2.DistanceMetersPow2) +
GetWeightedValue(orderItemsCount, MagicHat.V2.OrderItemsCount) +
GetWeightedValue(physicalItemsCount, MagicHat.V2.PhysicalItemsCount) +
GetWeightedValue(ordersInRealisationCount, MagicHat.V2.OrdersInRealisationCount) +
GetWeightedValue(workingCouriersCount, MagicHat.V2.WorkingCouriersCount) +
GetWeightedValue(ordersCountCourierRatio, MagicHat.V2.OrdersCountCourierRatio) +
GetWeightedValue(timeOfDay, MagicHat.V2.TimeOfDay) +
GetWeightedValue(dayOfWeek, MagicHat.V2.DayOfWeek) +
GetWeightedValue(temperature, MagicHat.V2.Temperature) +
GetWeightedValue(precipitation, MagicHat.V2.Precipitation) +
GetWeightedValue(snowfraction, MagicHat.V2.Snowfraction) +
GetWeightedValue(snowPrecipitation, MagicHat.V2.SnowPrecipitation) +
MagicHat.V2.B;
}
private static double GetWeightedValue(double x, Variable variable)
{
var scaledX = (x - variable.Mean) / variable.Scale;
return variable.Weight * scaledX;
}
}
Sieć neuronowa natomiast wymagałaby od nas postawienia dedykowanego serwisu pythonowego, który ładowałby model przy pomocy biblioteki oraz wystawiał API pozwalające na pobieranie estymat. Jest to nieporównywalnie bardziej czasochłonne pod kątem wdrożenia i utrzymania, dlatego zdecydowaliśmy się nie wdrażać tego modelu na produkcję. Okazało się, że regresja liniowa jest dla nas wystarczająco dobra :)
Co jeszcze przed nami?
Brakuje nam jednej, bardzo ważnej rzeczy: Nie retrenujemy naszego modelu. Został on wytrenowany raz i od tej pory nie zaktualizowaliśmy parametrów. Realia naszego biznesu i otoczenia się zmieniają, dlatego regularne retrenowanie modelu na świeżych danych jest kluczowe dla skuteczności naszego oraz każdego innego rozwiązania opartego o uczenie maszynowe. Mamy w planach implementację automatycznego rozwiązania, które cyklicznie pobierze dane z bazy danych, wykona na nich wymagane operacje, wytrenuje model oraz zaktualizuje stałe w naszym kodzie. Wymaga to jednak użycia innych, bardziej skomplikowanych narzędzi niż Jupyter Notebook, dlatego zostawiliśmy to na następną iterację, w międzyczasie skupiając się na istotniejszych biznesowo zagadnieniach.