
10 deploymentów dziennie w 2009
W 2009 roku John Allspaw i Paul Hammond wyszli na scenę konferencji Velocity i powiedzieli, ze Flickr wdraża na produkcję ponad 10 razy dziennie. Początkowo odebrano to jako żart. W 2009 większość firm potrzebowała 4-6 tygodni na wdrożenie dużego systemu. To było wydarzenie z inżynierami dyżurującymi po godzinach, pizzą i pilnowaniem, aby wszystko poszło ok. 10 razy dziennie brzmiało jak sabotaż.
Częste wdrożenia przyspieszają tempo uczenia się organizacji (zobacz “Organizational Learning and Competitiveness”). Flickr mógł testować hipotezy 10 razy dziennie. Ich konkurencji - raz w miesiącu. Ta ultra-szybka informacja zwrotna daje niesamowitą przewagę nad konkurencją.
Obecnie systemy backendowe liska rozwija zespół liczący zaledwie kilku programistów. Dzięki doświadczeniu i odpowiednim praktykom inżynieryjnym w ciągu miesiąca wdrażamy zmiany blisko 100 razy. Bywają dni z 9 deploymentami, więc zbliżamy się do wyników Flickr, osiągając to z zespołem dziesięciokrotnie mniejszym.
W tym artykule opowiem o transformacji, jaką przeszedł zespół, największych wyzwaniach i następnych krokach.
Punkt wyjścia
Niecały rok temu sytuacja była diametralnie odwrotna. Bywały tygodnie z pojedynczymi wdrożeniami, długimi testami manualnymi i częstszymi hot-fixami.
Większość logiki była zaimplementowana w dużym, .netowym monolicie. Testy automatyczne były szczątkowe, brakowało testów integracyjnych i end-to-end. Sam proces wdrożenia na produkcję był ręczny i obejmował kilkanaście kroków. Sam zespół podzielony był horyzontalnie na zespół backendowy i mobilny.
W języku metryk DORA bylibyśmy low performerem ale nie mieliśmy nawet metryk aby to zmierzyć.
Zmiany
Goldratt w “The Goal” twierdzi, że każde usprawnienie które nie dotyczy wąskiego gardła jest iluzją.
Pierwsze ograniczenie było nie było techniczne. Był nim strach przed wdrożeniami. Wdrożenia były ryzykowne, ponieważ były duże. Były duże, ponieważ wykonywaliśmy je rzadko. To błędne koło, w którym ryzyko wynika z rzadkości, a rzadkość z ryzyka, było naszym pierwszym wąskim gardłem.
Pierwsza zmiana nie miała nic wspólnego z kodem. Podzieliliśmy zespół na dwa zespoły produktowe, każdy z tech leadem i jasnym zakresem odpowiedzialności. W “Team Topologies” to się nazywa stream-aligned teams - zespoły zorientowane na strumień wartości. Powołaliśmy też gildie technologiczne do rozwiązywania problemów wspólnych: infrastruktura testowa, standardy kodu, pipeline.
Następnie zabraliśmy się za pokrycie aplikacji testami. Było to sporym wyzwaniem, bo większość logiki biznesowej była zaimplementowana w ogromnych klasach z kilkunastoma zależnościami.
Podjęliśmy kluczową decyzję, by zacząć od testów integracyjnych na prawdziwej aplikacji i implementację złotych testów dla najważniejszych ścieżek w aplikacji.
Odseparowaliśmy również proces wdrożenia (deploymentu) od udostępnienia nowej wersji aplikacji użytkownikom (releasu). Wdrożenie to umieszczenie kodu na produkcji. Release to udostępnienie funkcjonalności użytkownikom. Kiedy rozdzielisz te dwa pojęcia, wdrożenie przestaje być decyzją biznesową. Udostępnienie funkcjonalności użytkownikom (release) może nastąpić w osobnym, kontrolowanym momencie, niezależnie od faktu umieszczenia kodu na produkcji.
Umożliwiły nam to feature flagi. Zaczęliśmy od prostych flag konfiguracyjnych w kodzie, dziś mamy feature flagi w bazie danych z bezpiecznikami dla krytycznych operacji. Jesteśmy w stanie wyłączyć dowolną funkcjonalność jednym kliknięciem, bez wdrożenia. Strach przed wdrożeniem po prostu zniknął.
W styczniu 2026 uruchomiliśmy pełen proces ciągłych deploymentów. Wcześniej wdrożenie wymagało ręcznego kliknięcia. Teraz każde wypchnięcie kodu do głównego brancha w repozytorium automatycznie przechodzi przez wdrożenie testowe, testy integracyjne, testy E2E i wdrożenie na produkcję. Jedyna ręczna bramka to code review PR-a.
Zaczęliśmy również dokładniej monitorować system na środowisku produkcyjnym. Poza ustrukturyzowanymi logami, które mieliśmy już wcześniej, dodaliśmy własne metryki i pełną instrumentację kluczowych procesów biznesowych. Wdrożyliśmy również bardziej formalny proces odpowiedzi na incydenty. Każda awaria skutkuje postmortemem. Uczymy się i usprawniamy system.
Gdzie jesteśmy
Gdzie teraz jesteśmy w języku metryk DORA? Z dumą mogę przyznać, że zespół dołączyć do elity zespołów inżynieryjnych.
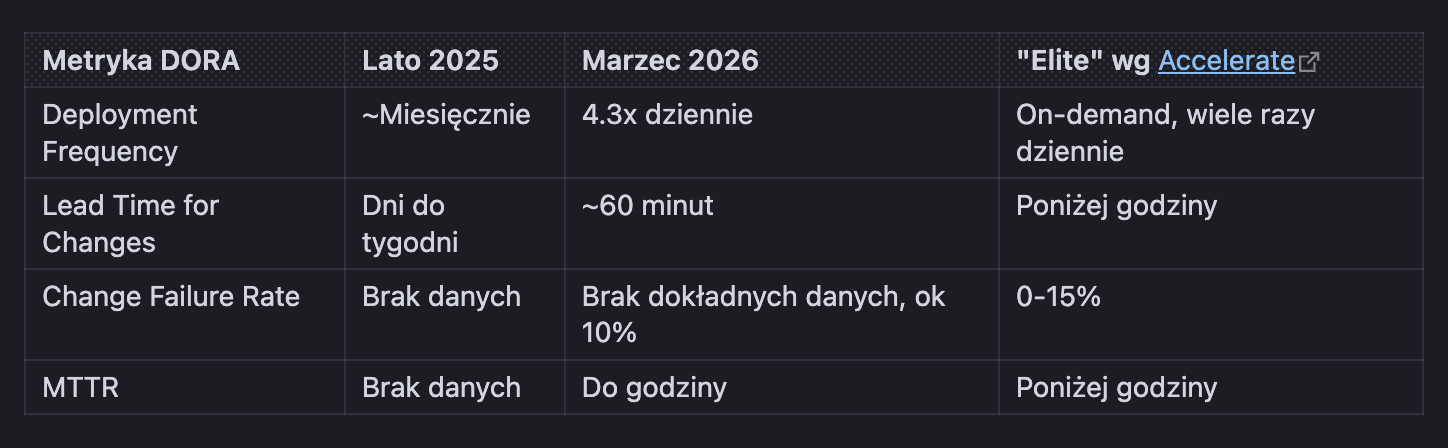
Widzimy gdzie jeszcze możemy poprawić nasze działania. Np. nie korelujemy jeszcze skoków ilości błędów z konkretnym wdrożeniem i nie mamy automatycznego procesu cofnięcia wdrożenia.
AI
Każda zmiana opisana wyżej dotyczyła tego co się dzieje po napisaniu kodu. Kiedy usuniesz te ograniczenia, wąskim gardłem staje się szybkość pisania kodu.
Wdrożyliśmy Claude Code - agenta AI który czyta cały kod, proponuje zmiany, uruchamia testy i iteruje. Podłączyliśmy go przez MCP do wewnętrznych narzędzi: bazy produkcyjnej , Jiry, Datadoga, Figmy. W praktyce AI ma ten sam kontekst co programista siedzący w zespole od roku.
Eksperymentujemy też ze spec-driven development - zanim zaczniemy pisać kod, zaprojektuje zmianę ze specyfikacją i listą zadań. Rozdziela to fazę myślenia od fazy pisania.
Ryzyko wdrażania kodu, którego nikt w pełni nie rozumie, jest realne, dlatego infrastruktura testowa i ciągłe dostarczanie (CD) zbudowane wcześniej stały się naszą najważniejszą siatką bezpieczeństwa.
Skróciliśmy czas od napisania kodu do produkcji do niecałej godziny. Teraz skracamy czas od pomysłu do kodu. Wierzę, że wkrótce jedynym naszym ograniczeniem będzie nasza wyobraźnia i generowanie odpowiednich pomysłów.