
Dwie aplikacje działające równolegle na produkcji. Zero downtime dla użytkowników. Brzmi prosto, ale jak zwykle diabeł tkwił w szczegółach.
W tym tekście opisuję, jak przeszliśmy z aplikacji opartej o Create React App na Next.js, dlaczego w ogóle zdecydowaliśmy się na rewrite, jakie decyzje technologiczne podjęliśmy po drodze i jak użyliśmy NGINX-a jako prostego, ale bardzo skutecznego przełącznika ruchu między starą i nową aplikacją. Nie był to rewrite robiony „bo fajnie byłoby mieć nowy stack”. To była migracja na żywym organizmie, z działającym sklepem, realnymi użytkownikami i biznesem, który nie zatrzymał się tylko dlatego, że frontend potrzebował generalnego remontu.
Dlaczego przepisaliśmy aplikację webową
Decyzja o przepisaniu aplikacji od zera nigdy nie jest komfortowa. Każdy, kto pracował przy większym produkcie, wie, co to oznacza: dużo pracy, dużo ryzyka i sporo kodu, który przez jakiś czas trzeba utrzymywać podwójnie. U nas ta decyzja dojrzewała przez kilka miesięcy. Nie była impulsem po jednym trudnym sprincie ani reakcją na modę na nowy framework. Powody były bardzo konkretne.
Stara aplikacja była oparta o Create React App, mocno zintegrowana z Reduxem i Material UI. Na papierze to nadal brzmi jak zupełnie rozsądny stack. Problem w tym, że po kilku latach rozwoju aplikacji stack to jedno, a sposób, w jaki obrasta go kod, to drugie.
Redux był praktycznie wszędzie. Nie tylko tam, gdzie faktycznie był potrzebny, ale też w miejscach, gdzie wystarczyłby lokalny stan albo prostszy mechanizm cache’owania danych z API. Z czasem zrobiło się z tego klasyczne spaghetti: akcje, reducery, selektory, efekty uboczne i logika biznesowa porozrzucana po różnych warstwach. Zmieniasz jedną rzecz, a regresja wychodzi w miejscu, którego nikt nie dotykał od miesięcy. Dodawanie nowych funkcjonalności zaczęło być coraz wolniejsze. Nie dlatego, że zespół nie wiedział, co robi, tylko dlatego, że sama aplikacja zaczęła wymuszać ostrożność przy każdej zmianie.
Drugim, a z perspektywy biznesu chyba jeszcze ważniejszym problemem, był brak SSR. CRA daje klasyczne SPA. Dla użytkownika po załadowaniu aplikacji może to działać dobrze, ale dla wyszukiwarki na starcie serwujemy głównie pusty szkielet. W e-commerce to nie jest detal techniczny. To bezpośrednio wpływa na widoczność produktów, kategorii i treści w Google, a więc finalnie na przychód. Strony, które powinny być indeksowane z pełną treścią, nie były traktowane tak, jak powinny. SEO było trudne do zrobienia porządnie, a część problemów wynikała z samej architektury aplikacji. W pewnym momencie stało się jasne, że dokładanie kolejnych łatek nie rozwiąże problemu.
Nowy stack
Wybór Next.js jako fundamentu nowej aplikacji był dla nas dość naturalny. Potrzebowaliśmy SSR, SSG, sensownego modelu routingu, dobrej integracji z Reactem i narzędzia, które nie będzie egzotyką dla zespołu ani dla rynku. App Router, Server Components, rendering po stronie serwera i statyczne generowanie stron pasowały do tego, czego potrzebowaliśmy. Startowaliśmy na Next.js 15, a obecnie aplikacja działa już na wersji 16.
Sam framework to jednak tylko baza. Dużo ważniejsze były decyzje wokół stanu, styli, autha i integracji.
TanStack Query był jedną z najlepszych decyzji w całym projekcie. W starej aplikacji za dużo danych z serwera żyło w Reduxie. Po migracji server state wylądował tam, gdzie powinien: w narzędziu zaprojektowanym do cache’owania, inwalidacji, refetchowania i obsługi stanów requestów. Nagle rzeczy, które wcześniej wymagały reducerów, akcji, efektów i ręcznego pilnowania kolejności requestów, zaczęły być opisane deklaratywnie. Cache przestał być czymś, co dopisujemy ręcznie przy okazji, a stał się częścią modelu pracy z API.
Zustand wzięliśmy do stanu stricte klienckiego i to był bardzo dobry kontrast do starego podejścia. Tam, gdzie Redux był armatą na muchę, Zustand dawał dokładnie tyle, ile było potrzebne: prosty store, mało boilerplate’u, łatwe składanie logiki i brak poczucia, że musimy budować architekturę do każdej drobnej interakcji.
Tailwind CSS zastąpił MUI i emotion. To nie była tylko wymiana jednej biblioteki do styli na drugą. To była zmiana podejścia. MUI przez lata dawał nam gotowe komponenty, ale jednocześnie narzucał swój sposób myślenia o UI. Do tego dochodził większy bundle i stylowanie oparte o runtime. Przy rosnącej aplikacji zaczęliśmy to czuć. Tailwind dał nam więcej kontroli, spójność przez design tokeny i znacznie prostszy model pracy z interfejsem. Stylowanie przestało być osobną warstwą problemów.
Do tego doszły: Auth.js do sesji i SMS OTP, Wretch jako klient HTTP z wygodnym łańcuchem middleware’ów, Radix UI jako fundament dostępnych komponentów oraz Vitest z React Testing Library do testów jednostkowych. Do Auth.js jeszcze wrócę, bo to akurat decyzja, której dziś bym już nie powtórzył. Reszty wyborów nie żałuję.
NGINX jako przełącznik
Najważniejszy element całej migracji był jednocześnie jednym z najprostszych, czyli NGINX. To on pozwolił nam migrować aplikację etapami, bez robienia wielkiego release’u w stylu „w piątek wieczorem przełączamy wszystko i liczymy, że będzie dobrze”.
Założenie było proste. Stara aplikacja w CRA i nowa aplikacja w Next.js działają równolegle na produkcji. NGINX patrzy na ścieżkę URL i decyduje, która aplikacja ma obsłużyć request. Użytkownik wchodzi na /sklep, dostaje nową aplikację. Wchodzi na /koszyk i nadal trafia do starej aplikacji. Bez feature flag. Bez A/B testów. Bez ukrytej logiki po stronie klienta. Po prostu deterministyczny routing po URL-ach.
W praktyce ustawiliśmy nową aplikację jako domyślną, a ścieżki, które nie były jeszcze zmigrowane, kierowaliśmy reverse proxy do starego CRA. Każde przeniesienie kolejnej strony oznaczało usunięcie jednej reguły z konfiguracji NGINX-a. Stara aplikacja traciła następny kawałek ruchu, a my nie musieliśmy ruszać kodu routingu ani w jednej, ani w drugiej aplikacji.
To dawało bardzo duży komfort operacyjny. Nowe strony trafiały do wszystkich użytkowników od razu, ale tylko na konkretnych ścieżkach. Jeśli coś się wysypało, problem był ograniczony do jednej części aplikacji. Rollback był prosty i szybki, czyli przywrócenie reguły w NGINX-ie. Każda strona była osobnym krokiem migracji, a nie częścią jednego wielkiego, ryzykownego przełączenia.
Konfiguracja sprowadzała się do kilku reguł. Nowa aplikacja w Next.js jako domyślny backend, a ścieżki, które nie były jeszcze zmigrowane, kierowane reverse proxy do starego CRA. Przykładowy i uproszczony config:
upstream next_app { server next:3000; }
upstream cra_app { server cra:8080; }
server {
listen 80;
server_name lisek.app;
location / {
proxy_pass http://next_app;
}
location ~ ^/(koszyk|ustawienia)(/|$) {
proxy_pass http://cra_app;
}
}
Żądanie na /sklep nie pasuje do żadnej reguły CRA, więc trafia do bloku domyślnego i obsługuje je Next.js. Żądanie na /koszyk łapie się na regule reverse proxy i ląduje w starym CRA. Migracja kolejnej strony to usunięcie jednej location, bez dotykania kodu routingu w żadnej z aplikacji.
Sesja między dwiema aplikacjami
Dwie aplikacje działają na jednej domenie. Użytkownik loguje się w jednej z nich, ale część ścieżek nadal obsługuje druga. Z jego perspektywy nie może być żadnej różnicy. Nie interesuje go, czy aktualnie jest w CRA, czy w Next.js. Ma być zalogowany, koszyk ma działać, profil ma działać, logout ma działać.
Najpierw zbudowaliśmy pełny mechanizm auth w nowej aplikacji: logowanie, rejestrację, SMS OTP, sesje anonimowe i refresh tokena. Postawiliśmy na Auth.js v5 z JWT trzymanym w cookie HttpOnly. Założenie było takie, że nowa aplikacja stanie się źródłem prawdy dla sesji, a stara będzie stopniowo sprowadzona do roli konsumenta.
Następnie wystawiliśmy po stronie Next.js endpointy, z których mogła korzystać stara aplikacja. Stare CRA mogło pobrać aktualną sesję na podstawie cookie, odświeżyć token i wykonać logout zsynchronizowany po obu stronach. Dzięki temu stara aplikacja nie musiała znać szczegółów implementacyjnych nowego autha. Dostawała gotowy stan sesji i działała dalej.
Na końcu przebudowaliśmy warstwę auth w starej aplikacji. Wycofaliśmy stary provider sesji, wymieniliśmy interceptory HTTP, a sign-in i sign-out zaczęły aktualizować stan w obu aplikacjach jednocześnie. Efekt docelowy był dokładnie taki, jakiego potrzebowaliśmy: użytkownik loguje się raz, a przechodzenie między ścieżkami obsługiwanymi przez dwie różne aplikacje jest dla niego niewidoczne.
Jeden problem wyszedł dopiero na produkcji: refresh tokena w środowisku z wieloma replikami bardzo łatwo wpada w race condition. A gdy obok siebie działają dwie aplikacje, szansa na równoległe requesty rośnie jeszcze bardziej. Scenariusz był prosty: dwa requesty prawie jednocześnie próbują odświeżyć token. Pierwszy dostaje nowy token i unieważnia stary. Drugi, który startował z tym samym starym tokenem, przegrywa i kończy z 401.
Rozwiązaliśmy to rozproszonym lockiem w Redisie. Refresh tokeny są serializowane na poziomie całego klastra, a nie pojedynczej instancji aplikacji. Dopiero to podejście rozwiązało ten problem poprawnie.
Natomiast samego wyboru biblioteki do auth dziś bym nie powtórzył. Postawiliśmy na Auth.js v5, licząc, że zdejmie z nas większość pracy wokół sesji, tokenów i providerów. W praktyce nasze flow było na tyle niestandardowe, że sporo czasu spędziliśmy na dopasowywaniu biblioteki do wymagań, zamiast korzystać z niej „po bożemu”. SMS OTP, sesje anonimowe, wspólna sesja dla dwóch aplikacji, dwa backendy auth w trakcie migracji. To nie był typowy przypadek użycia. Finalnie dostaliśmy abstrakcję, której nie potrzebowaliśmy, a straciliśmy kontrolę nad fragmentami, które musieliśmy kontrolować bardzo precyzyjnie.
Finalnie stoi przed nami jeszcze jedna migracja, czyli wyjście z Auth.js na własne, prostsze rozwiązanie albo na bibliotekę, która lepiej pasuje do naszego modelu. Lekcja jest prosta: jeśli auth w aplikacji nie mieści się w standardowym flow, czasem szybciej i łatwiej jest napisać kod samemu, niż naginać dużą abstrakcję do nietypowego przypadku.
Kolejność migracji
Migrację prowadziliśmy strona po stronie, zaczynając od najmniej ryzykownych miejsc.
Pierwsza była strona statusu zamówienia. Nie wymagała jeszcze pełnego autha, bo token potrzebny do podejrzenia zamówienia mogliśmy przekazać innym mechanizmem. To był dobry kandydat na sprawdzenie całego podejścia w produkcji. Sama strona była stosunkowo prosta i mało interakcyjna, ale dała nam bardzo dużo informacji. Przetestowaliśmy cały pipeline: deployment, routing przez NGINX, SSR, monitoring, logi i zachowanie aplikacji pod realnym ruchem.
Później przyszły logowanie i rejestracja, czyli pierwszy większy fragment z realną logiką biznesową. Zaraz po tym przebudowaliśmy auth w starej aplikacji tak, żeby delegował sesję do nowej.
Kiedy auth był gotowy, mogliśmy ruszyć z ważniejszymi stronami. Najpierw przenieśliśmy stronę główną, która jako pierwsza w pełni skorzystała z SSR. Potem poszły kategorie i produkty, czyli serce sklepu i jednocześnie miejsca, które najbardziej potrzebowały renderowania po stronie serwera oraz poprawnej indeksacji.
W międzyczasie przenieśliśmy całą warstwę treści statycznych: regulaminy, politykę prywatności, FAQ, informacje o dostawie i płatnościach. Napisaliśmy je w MDX i wyrenderowaliśmy jako SSG. To dało bardzo dobry performance praktycznie bez dodatkowego kosztu.
Dalej migrowaliśmy strony listingowe: wyszukiwarkę, popularne produkty, rekomendacje, ulubione i „kup ponownie”. Doszły gazetki promocyjne, landing pages kampanii, strona misji i podgląd paragonów w PDF.
Osobnym kawałkiem były deeplinki z aplikacji mobilnej. Stare URL-e typu /category/[key] i /product/[EAN] nadal funkcjonowały w obiegu, więc musieliśmy zadbać o to, żeby trafiały w odpowiednie miejsca w nowej aplikacji, bez psucia istniejących linków.
Później zabraliśmy się za rzeczy wymagające pełnego autha: profil użytkownika, historię zamówień i ustawienia konta.
Na sam koniec zostawiliśmy koszyk. To najbardziej krytyczne biznesowo miejsce w całej aplikacji. Każdy błąd w koszyku to potencjalnie utracona transakcja, więc nie chcieliśmy dotykać go za wcześnie. Najpierw nowa aplikacja musiała przez kilka miesięcy popracować na produkcji i udowodnić, że jest stabilna.
Przepisywanie na żywym organizmie
Na osi czasu ta migracja wygląda dość logicznie: najpierw proste strony, potem auth, potem coraz bardziej krytyczne obszary. W praktyce było mniej elegancko, bo aplikacja nie czekała grzecznie, aż ją przepiszemy.
Biznes działał dalej. Aplikacje mobilne dostawały nowe funkcjonalności. Web musiał nadążać. Nie było możliwości zamrożenia feature’ów na czas migracji, bo użytkownicy oczekiwali tych samych możliwości niezależnie od platformy. To oznaczało, że równolegle z przepisywaniem istniejących stron musieliśmy dowozić nowe rzeczy. Jeśli nowy feature dotyczył strony, która nie była jeszcze zmigrowana, często budowaliśmy go w starej aplikacji, mając świadomość, że za kilka tygodni lub miesięcy będziemy musieli przepisać go drugi raz. Czasem dało się przyspieszyć migrację konkretnej strony i uniknąć podwójnej pracy, ale nie zawsze było to możliwe.
To był jeden z najtrudniejszych organizacyjnie elementów całego projektu. Linia mety ciągle się przesuwała. Aplikacja, którą mieliśmy przepisać, rosła w trakcie przepisywania. Każdy nowy feature oznaczał nie tylko pracę „tu i teraz”, ale też zwiększenie zakresu samej migracji. I to właśnie ten efekt, bardziej niż pojedynczy problem techniczny, najmocniej wydłużył cały proces.
Porządek z integracjami
Rewrite dał nam też dobrą okazję do posprzątania tematu, który przez lata rósł trochę bez kontroli: integracji marketingowych i analitycznych.
W starej aplikacji tagi, eventy i integracje były rozsiane po kodzie. Część rzeczy była dopinana szybko pod konkretne kampanie, część zostawała na dłużej, część przestawała być używana, ale nadal istniała w kodzie. Po czasie trudno było powiedzieć, co dokładnie się odpala, kiedy i dlaczego.
W nowej aplikacji przyjęliśmy prostą zasadę: aplikacja odpowiada tylko za wypchnięcie zdarzeń do dataLayer, a całą resztą zarządza Google Tag Manager. To on stał się źródłem prawdy, a nie porozrzucane po komponentach wywołania konkretnych narzędzi. Dzięki temu marketing może dodać albo zmienić tag bez ruszania kodu i czekania na deploy, a my mamy jedno miejsce, w którym widzimy, jakie eventy faktycznie wysyła aplikacja.
Drugą rzeczą, którą zrobiliśmy od razu porządnie, był consent mode. Google Consent Mode v2 wdrożyliśmy przez GTM razem z Cookie Script, tak żeby zgoda użytkownika realnie decydowała o tym, które tagi mogą się uruchomić.
Wyłączenie starego świata
Moment, w którym koszyk przeszedł na nową aplikację, był dla nas symboliczny. Po tej migracji nie było już nic, co realnie trzymało starą aplikację przy życiu. Wyłączenie CRA, usunięcie reguł z NGINX-a i zostawienie samego Next.js było jednym z najbardziej satysfakcjonujących etapów całego projektu.
Nagle uprościło się prawie wszystko: deployment, infrastruktura, debugowanie, monitoring i samo myślenie o systemie. Zniknęło pytanie „w której aplikacji jest ta funkcjonalność?”. Została jedna aplikacja i jeden kierunek rozwoju.
Namacalne efekty biznesowe
Najpierw zobaczyliśmy poprawę wydajności. Aplikacja stała się zauważalnie szybsza, stabilniejsza i przyjemniejsza w korzystaniu.
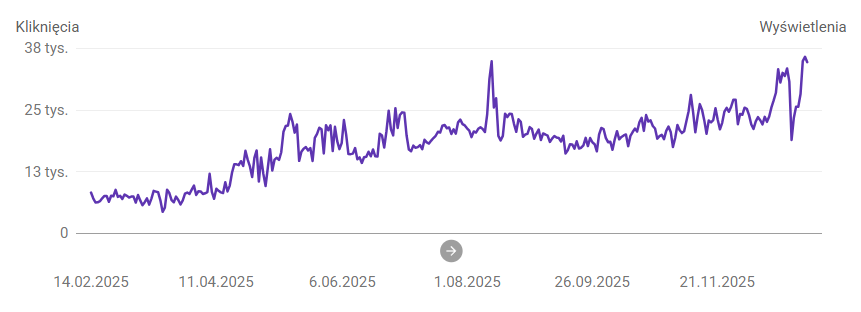
Drugi efekt to SEO, czyli jeden z głównych powodów całej migracji. Po przejściu na SSR i indeksowaniu stron z pełną treścią ruch organiczny wzrósł, a Google w końcu dostawało prawdziwą zawartość strony, a nie pusty szkielet aplikacji SPA.
Trzecia zmiana jest mniej efektowna na pierwszy rzut oka, ale bardzo ważna, bo w końcu zaczęliśmy ufać własnym danym. Po uporządkowaniu integracji i analityki raporty przestały być zbiorem liczb, do których trzeba podchodzić z dużą ostrożnością. Decyzje produktowe i marketingowe zaczęliśmy opierać na danych, które faktycznie odzwierciedlają zachowanie użytkowników. W kampaniach przełożyło się to na spadek kosztu konwersji. Nie dlatego, że wydarzyła się magia, tylko dlatego, że optymalizacja na czystszych danych działa po prostu lepiej.
Czego się nauczyliśmy
Migracja przez NGINX okazała się jednym z najprostszych i najbardziej praktycznych podejść do rewrite’u aplikacji webowej bez big bang release’u. Routing po URL-ach jest łatwy do zrozumienia, łatwy do debugowania i łatwy do odwrócenia. Nie wymaga skomplikowanej infrastruktury ani rozbudowanego systemu feature flag. W naszym przypadku był dokładnie tym poziomem prostoty, którego potrzebowaliśmy.
Największym ryzykiem był auth. Dopóki nie masz dobrze rozwiązanego współdzielenia sesji między aplikacjami, wszystko inne będzie się o to potykać. Gdy auth zaczął działać stabilnie, reszta migracji była już głównie kwestią czasu, priorytetów i konsekwentnego dowożenia kolejnych stron.
Kolejna ważna lekcja dotyczy stanu aplikacji. TanStack Query zastąpił nam dużą część zastosowań Reduxa lepiej, niż zakładaliśmy. Jeśli większość Twojego store’a to dane z serwera, prawdopodobnie nie potrzebujesz globalnego state managementu w stylu Reduxa. Potrzebujesz dobrego narzędzia do pracy z server state. Dla tej części stanu, która faktycznie jest kliencka, Zustand okazał się w zupełności wystarczający.
To jest chyba szerszy wniosek z całego projektu: nie warto wybierać narzędzi tylko dlatego, że „tak się robi w dużych aplikacjach”. Duża aplikacja nie zawsze potrzebuje najcięższego możliwego rozwiązania. Narzędzie trzeba dobrać do problemu, nie do rozmiaru prezentacji architektonicznej.
Najważniejsze jest to, że przez całą migrację ani razu nie musieliśmy wyłączyć aplikacji dla użytkowników. Każda zmiana była wprowadzana w locie. Sklep działał normalnie, użytkownicy robili zakupy, a my kawałek po kawałku wymienialiśmy fundamenty pod spodem. Z perspektywy czasu, właśnie to było warte tych kilku trudniejszych miesięcy.